概览
这次要爬的数据来自网站:http://www.qlaee.com/zhuanlist.jsp?flag=3&p=1&columnumber=302&codemyid=qlpreweb21
界面大概是这样的: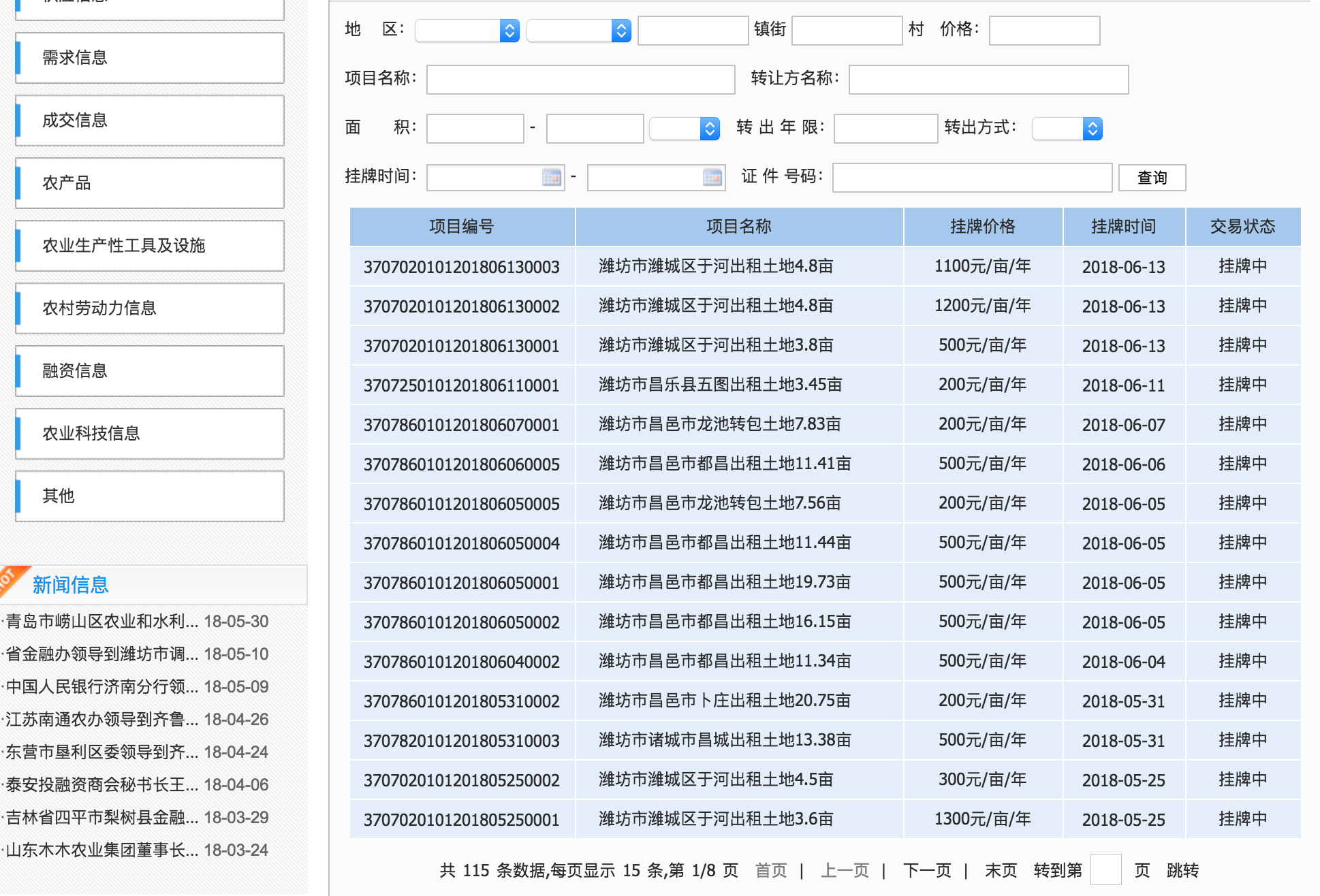
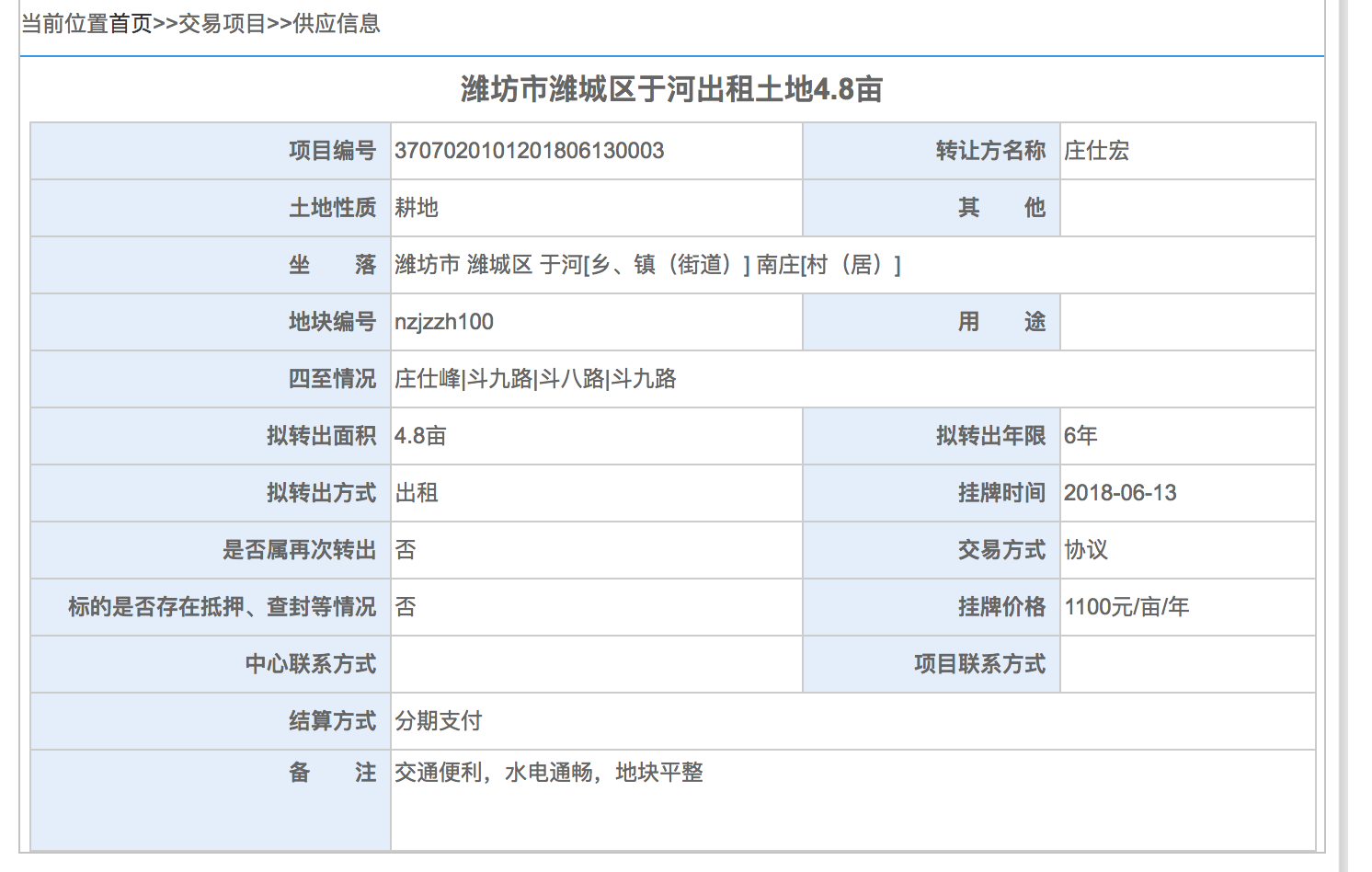
需要的数据就是图中的表格,表格的每一项都还有详情页面,如下图:
处理第一个页面
上图表格可以看到,这个数据共有8页,对于多页的处理,需要找到其页面的网址,然后通过页面网址的序号进行多页面的遍历。
我们把鼠标右击下一页,复制下一页的网址,看到如下:
其实也可以再获取下一页的网址,对比,发现变化的是p=2,所以对这8页的处理逻辑为
for i in range(1, 9):
url = "http://www.qlaee.com/news_list3.jsp?p=" + str(i) \
+ "&columnumber=302&countyid=&outareat=&areaunit=&cityid=&baseprice=&codemyid=qlpreweb21&outareaf="
得到每个页面的网址,就可以用requests进行页面爬取。
html = requests.get(url).content.decode('utf-8')
爬到的页面部分关键数据如下:
项目编号
项目名称
挂牌价格
挂牌时间
交易状态
3707020101201806130003
潍坊市潍城区于河出租土地4.8亩
1100元/亩/年
2018-06-13
挂牌中
3707020101201806130002
潍坊市潍城区于河出租土地4.8亩
1200元/亩/年
2018-06-13
挂牌中
拿到源码数据,就需要使用 BeautifulSoup 对源码进行解析。不过解析前需要分析一下代码结构。
表格数据是标准的 <tr><td> 标签,但因为界面上还有其他的表格,所以不能直接过滤 <tr><td> 。通过对比,我们需要的每一行数据包裹在 <tr class="x_hei"> ,所以过滤 x_hei 即可。
soup = BeautifulSoup(html, 'html.parser')
trs = soup.find_all('tr', attrs={'class': 'x_hei'})
拿到所有的 <tr> ,即表格的每一行。 <trs> 是个 list ,先看下标题数据:
[项目编号 ,
项目名称 ,
挂牌价格 ,
挂牌时间 ,
交易状态 ]
遍历该list,提取每一行的文字内容即可。对文字的提取,可以看到规律,文字包裹在 > </中,所以用正则表达式就可以轻松拿到想要的数据。
for index, item in enumerate(td):
item = str(item)
pattern = re.compile(r'>(.*?)
然后看下具体内容数据:
[
3707020101201806130003 ,
潍坊市潍城区于河出租土地4.8亩 ,
1100元/亩/年 ,
2018-06-13 ,
挂牌中 ]
和标题略有一些出入,内容前两项包裹在 <a> 中,即有着对应内容的网址链接,中间两项在 <td>中,最后一项在一个<span>中。
所以需要另外处理这些内容
if index == 0:
result = re.findall(r'(.*?)', item, re.S | re.M)
link = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 2:
result = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 3:
result = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 4:
result = re.findall(r'(.*?)', item, re.S | re.M)
这里注意,使用一个全局的web_list保存网址链接,用作下一步的页面爬取。
到这里,这个页面的数据就爬取完成。
详情页数据提取
依然先用requests获取页面数据,然后使用同样的方法处理数据。这里主要提一下差异:
通过提取源码,知道这个页面表格被 <div> 包裹:
潍坊市潍城区于河出租土地4.8亩
项目编号
3707020101201806130003
转让方名称
庄仕宏
土地性质
耕地
其他
坐落
潍坊市 潍城区 于河[乡、镇(街道)] 南庄[村(居)]
地块编号
nzjzzh100
用途
四至情况
庄仕峰|斗九路|斗八路|斗九路
拟转出面积
4.8亩
拟转出年限
6年
拟转出方式
出租
挂牌时间
2018-06-13
是否属再次转出
否
交易方式
协议
标的是否存在抵押、查封等情况
否
挂牌价格
1100元/亩/年
中心联系方式
项目联系方式
结算方式
分期支付
备注
交通便利,水电通畅,地块平整
所以先拿到对应的 <div>
div = soup.find_all('div', attrs={'class': 'content-list1'})[0]
再看其内部数据
主标题,被
<h3>包裹<h3 class="no-line">潍坊市潍城区于河出租土地4.8亩</h3>数据标题,被
<th>包裹<th width="28%" height="24" align="right" bgcolor="#E4EEFA" >项目编号 </th>数据内容,被
<td>包裹<td width="32%" >3707020101201806130003</td>特殊项,被
<span>包裹<th height="48" align="right" valign="top" bgcolor="#E4EEFA" ><span style="letter-spacing: 2em;margin-right: -2em;">备注</span> </th>
知道这些,就可以按照观察到的进行分别处理,先把标题全部取出来存到一个list中,再把数据全部取数来按顺序存到另一个list中即可。
def get_detail(iurl):
print("handling url:" + iurl)
html = requests.get(iurl, timeout=10).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
# print(soup)
div = soup.find_all('div', attrs={'class': 'content-list1'})[0]
# for title
if len(list2) == 0:
title_list = []
title_list.append("项目名称")
ths = div.find_all('th')
for th in ths:
th = str(th)
text = re.findall(r'(.*?)', th, re.S | re.M)
if len(text) is 0:
text = re.findall(r'(.*?)', th, re.S | re.M)
result = text[0].strip()
title_list.append(result)
list2.append(handle_list(title_list))
# for content
tmp_list = []
title = div.find_all('h3')
pattern = re.compile(r'>(.*?)(.*?)', td, re.S | re.M)
if len(text) is 0:
text = [""]
result = text[0].strip()
tmp_list.append(result)
list2.append(handle_list(tmp_list))
数据保存
前面的数据都存在一个list中,最后的展示,当然是存在excel中比较好,所以建议使用openpyxl,因为支持xlsx格式。
def save_list_to_excel(listX, name):
file_path = '/Users/wow/Desktop/spider.xlsx'
if os.path.exists(file_path):
wb = openpyxl.load_workbook(file_path)
else:
wb = openpyxl.Workbook()
ws = wb.create_sheet(title=name)
for index_x, row in enumerate(listX):
for index_y, col in enumerate(row):
ws.cell(index_x + 1, index_y + 1, col)
wb.save(filename=file_path)
使用很简单,先判断文件是否存在,不存在新建表格,存在打开表格,在原来基础上按顺序添加新内容即可。
完整代码
整体的代码很简单。为了代码易读,所以都用的最基本的语法。后面会增加一些多进程处理页面,也会对页面处理方法进行封装,尽量适配更多的相似页面。
# coding: utf-8
import requests
from bs4 import BeautifulSoup
import re
import openpyxl
import os
list1 = []
web_list = []
list2 = []
def fetch_page1(index, item):
global web_list
if index == 0:
result = re.findall(r'(.*?)', item, re.S | re.M)
link = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 2:
result = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 3:
result = re.findall(r'(.*?)', item, re.S | re.M)
elif index == 4:
result = re.findall(r'(.*?)', item, re.S | re.M)
else:
result = []
if len(result) > 0:
return result[0]
else:
return ""
def get_page():
global list1
get_title = True
for i in range(1, 2):
print("handling page " + str(i))
# url = "http://www.qlaee.com/chengjlist.jsp?p=" + str(i) \
# + "&columnumber=-1&codemyid=qlpreweb23"
url = "http://www.qlaee.com/news_list3.jsp?p=" + str(i) \
+ "&columnumber=302&countyid=&outareat=&areaunit=&cityid=&baseprice=&codemyid=qlpreweb21&outareaf="
html = requests.get(url).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
trs = soup.find_all('tr', attrs={'class': 'x_hei'})
if get_title is False:
trs.pop(0)
for tr in trs:
tmp_list = []
td = tr.find_all('td')
print(td)
if len(td) < 0:
continue
for index, item in enumerate(td):
item = str(item)
if get_title is True:
pattern = re.compile(r'>(.*?)(.*?)', th, re.S | re.M)
if len(text) is 0:
text = re.findall(r'(.*?)', th, re.S | re.M)
result = text[0].strip()
title_list.append(result)
list2.append(handle_list(title_list))
# for content
tmp_list = []
title = div.find_all('h3')
pattern = re.compile(r'>(.*?)(.*?)', td, re.S | re.M)
if len(text) is 0:
text = [""]
result = text[0].strip()
tmp_list.append(result)
list2.append(handle_list(tmp_list))
def save_list_to_excel(listX, name):
file_path = '/Users/wow/Desktop/spider.xlsx'
if os.path.exists(file_path):
wb = openpyxl.load_workbook(file_path)
else:
wb = openpyxl.Workbook()
ws = wb.create_sheet(title=name)
for index_x, row in enumerate(listX):
for index_y, col in enumerate(row):
ws.cell(index_x + 1, index_y + 1, col)
wb.save(filename=file_path)
def handle_list(list_ori):
list_end = list_ori[-12:]
list_start = list_ori[0:-12]
for i, item in enumerate(list_end):
list_start.insert(6 + i, item)
return list_start
if __name__ == "__main__":
get_page()
if len(web_list) > 0:
for index, url in enumerate(web_list):
get_detail(url)
save_list_to_excel(list2, "detail")
最后恭喜阿根廷小组赛突围
现在阿根廷中后场整体不行,进世界杯都磕磕绊绊,后面淘汰赛估计也够呛了。


![[Android][Framework]系统手势和状态栏](/medias/featureimages/9.jpg)